
NOTE: This post was recovered from archives and unfortunately some of the images were lost. I’ve restored as much as I can. However, due to the age of this post I won’t be re-producing the missing images.
I recently read NoSQL Distilled by Pramod J. Sadalage and Martin Fowler. In the book, an argument is put forth that we are entering into an era of polyglot persistence, where applications use different storage technologies to handle different storage needs. The de-facto standard of using a relational database management system (RDBMS) for all storage needs is being challenged by some interesting NoSQL alternatives. In this book, discussion is given to five categories of databases; RDBMS, Key-Value, Document, Column, and Graph. I recommend the book if you want to gain a deeper understanding of these database categories. If you just want a quick primer in less than 1 hour, check out this video.
So, what could polyglot persistence look like? A canonical example is an online retail application as shown here.
(missing image #1 here)
In this example, we have a web-front-end (WFE) making use of different database categories for different needs. For example,
- When a user adds an item to his/her shopping cart, that shopping cart data may be stored using a key-value database. Key-Value databases provide fast access to simple, unstructured structured data. The key could be the user’s e-mail address with the value being individual shopping cart items.
- Product data can vary greatly from one product to the next. Just drill into the product details of your favorite online retailer and you will likely see different properties for different categories of products. In a RDBMS implementation, you can probably imagine schemas that have columns like “customfield1”, “customfield2”, and so on. Or all-encompassing schemas where each row has a lot of null values in it. Document database don’t enforce schema like a RDBMS does, and therefore a perfect fit for product data. You just store the product information as a document.
- Recommendation data such as “users who bought X also bought Y” is handled exceptionally well by graph databases. Here, nodes (users) can have any number of relationships (bought X, bought Y) and these relationships can evolve without requiring any schema changes. Furthermore, the nodes and, relationships between nodes, can each have properties associated with them to further enhance node traversal.
- The ACID characteristics of RDBMS is still a great fit for data such as order data, where the processing of payment and updating of inventory can easily be done in a manner that insures data integrity.
Something to observe here is that while we’re making use of different databases for different needs, we’ve also introduced a massive amount of complexity. The WFE needs to know how to do CRUD against four different databases now.
As a result of this, another pattern is emerging whereby database implementations are wrapped by web services. Consider now a cloud architecture such as this, where the underlying database (Key-Value, Document, Graph, and RDBMS) is wrapped by a web service and the WFE simply retrieves the URI for these services from its web.config file.
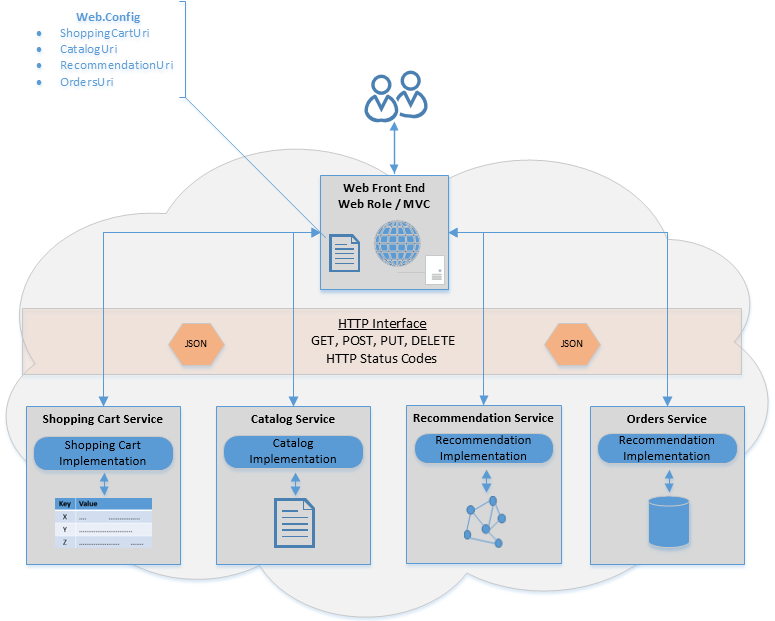
This is a good idea when you’re using multiple database technologies as it eliminates direct dependencies to the databases that the WFE would otherwise have to take. With this design, the WFE just consumes the web services using standard web protocols (HTTP, JSON), hiding the complexities of the underlying database. This also offers the web service flexibility to change the database it uses in the future without introducing breaking changes.
By deploying this as a Windows Azure Cloud Service, you can begin to take advantage of the elastic scale of cloud computing. For example, the WFE and each underlying web service can be a separate role. Need more instances of the WFE? Fewer instances of the Shopping Cart Service? No problem – scale each as needed.
This gives you an idea of what polyglot persistence could look like in a Windows Azure Cloud Service. In future posts, I’ll be exploring some of the implementation details for each of these services.
Comments powered by Disqus.